Kunstig intelligens (KI) er utvikling av datasystemer som skal lære av erfaringer og utføre oppgaver i ulike situasjoner og miljøer. Maskiner som kan løse problemer og erstatte enkelte kognitive funksjoner hos et menneske kan være ressursbesparende. Regjeringen (1) definerer KI slik:
«Kunstig intelligente systemer utfører handlinger, fysisk eller digitalt, basert på tolkning og behandling av strukturerte eller ustrukturerte data, i den hensikt å oppnå et gitt mål. Enkelte KI-systemer kan også tilpasse seg gjennom å analysere og ta hensyn til hvordan tidligere handlinger har påvirket omgivelsene.»
I denne artikkelen ser vi på utfordringer og muligheter med programvare basert på KI.
Kunstig intelligens, nettsider og chat
De fleste av oss er kjent med bruk av søkemotorer på Internett, og stadig flere nettsider tilbyr samtale via chatbot. Begge typer grensesnitt bruker i økende grad KI-teknologi og er i kontinuerlig utvikling. Nettsøk gir deg informasjon direkte, og målet er at denne informasjonen skal presenteres mest mulig oppsummert og leservennlig slik at du slipper å klikke deg videre til nye nettsider. Med chatbot kan du gjennom en samtale få mer spesifikke svar. I praksis snakker du med en robot («KI-assistent») som hjelper deg til å nå et gitt mål.
Når det gjelder søkemotorer er det gjerne Microsofts Bing og Google som nevnes, og begge firma har utviklet chatbots basert på KI. Bard fra Google og Microsoft Bings AI (nå kalt Copilot) er eksempler på sistnevnte. Det foreligger i dag en rekke chatbots med ulike styrker og svakheter (2), og de oppgraderes forløpende. Mest omtalt er nok OpenAIs ChatGPT, som også er integrert i Bing/Copilot. ChatGPT bruker Natural Language Processing (NLP) og maskinlæring for å skape samtaler med mennesker, og lærer selv fortløpende av samtalene (2).
ChatGPT kan gi råd, skape tekstbaserte historier eller artikler og til og med fungere som din digitale assistent. Verktøyet er i stand til å forstå sammenhengen i en samtale og tilpasse seg brukerens intensjoner og preferanser. ChatGPT har ikke noen bevissthet eller ekte forståelse av verden. Det representerer en sofistikert modell for tekstgenerering som responderer på inndata basert på den konteksten den har blitt trent på (3).
ChatGPT og legemiddelspørsmål
Kliniske farmakologer ved legemiddelinformasjonssenteret i Odense undersøkte om en KI-plattform som ChatGPT kunne skrive en troverdig vitenskapelig tekst (4). Det danske senteret besvarer kliniske, legemiddelrelaterte spørsmål med korte oversiktsartikler (mini-reviews) basert på omfattende litteratursøk og interne diskusjoner, altså ikke ulikt arbeidsmetoden i RELIS. De sammenlignet sitt eget svar på spørsmål om sikkerhet ved bruk av metylfenidat i svangerskap og mulige bivirkninger av legemiddelet på kvinnelig fertilitet i forhold til svar fra to versjoner av ChatGPT (versjon 3 og 4). En gjennomgang av referansene i svarene fra ChatGPT viste at chatboten produserte fiktive referanser, falske resultat, og alternative konklusjoner fra studier (4).
Kliniske farmasøyter i Beijing sammenlignet ChatGPT4 og egne svar i forhold til tema som legemiddelgjennomgang, opplæring av pasienter, identifikasjon av bivirkninger og vurdering av kausalitet, og rådgivning om legemidler (5). I studien ble spørsmål fra aktuelle kliniske kasus i tillegg til spørsmål brukt for å vurdere klinisk farmasøytisk kompetanse i utdanningsformål brukt. I rådgivning om legemiddelbruk besvarte ChatGPT tilfredsstillende for de fleste spørsmål, men eksempelvis råd for å unngå interaksjon mellom soyamelk og levotyroksin var upraktisk i forhold til det virkelige liv. For de andre kategoriene av klinisk farmasi leverte ChatGPT dårligere, og ved legemiddelgjennomgang var verktøyet svakt i forhold til legemiddelrelaterte problemer ved bruk av tradisjonell kinesisk medisin. ChatGPT var relativt svak på identifikasjon av bivirkninger og vurdering av kausalitet (5).
Klinisk beslutningstøtte i forhold til avmedisinering av benzodiazepiner ble undersøkt i en kroatisk kohort (n = 154) av hjemmeværende pasienter (6). Vurdering av helsepersonell var basert på etablerte kriterier for avmedisinering av benzodiazepiner, og deres vurdering ble sammenlignet med ChatGPT4. Datamaterialet bestod av en omfattende geriatrisk beskrivelse av hver enkelt pasient. Forskerne fant relativt høyt samsvar mellom de respektive kildene, men observerte et behov for revisjon av beslutningstøtte fra ChatGPT. I 4 av tilfellene fant chatboten et legemiddelsikkerhetsproblem i form av mulige bivirkninger som pasienten selv ikke rapporterte (6).
To postere presentert på American Society of Health-System Pharmacists 2023 Midyear Clinical Meeting and Exhibition så på hvor nøyaktig og fullstendig ChatGPT formidlet legemiddelinformasjon (7, 8). En gruppe av legemiddelinformasjonsspesialister fra Long Island University samlet 45 spørsmål fra januar 2022 til april 2023, og utformet svar i mai 2023. ChatGPT besvarte 10 av 39 spørsmål tilfredsstillende. Av 29 spørsmål som ikke var nøyaktige og fullstendige nok, ble 11 besvart generisk i form av formidling av generell bakgrunnsinformasjon (7).
Forskere fra Iwate Medical University i Japan sammenlignet legemiddelinformasjon om bivirkninger mellom Lexicomp og ChatGPT for 30 legemidler godkjente av FDA. Spørsmålet til ChatGPT var «hva er de vanligste bivirkningene for dette legemiddelet?». Tjueseks av 30 svar fra ChatGPT var unøyaktige, 2 var delvis nøyaktige og 2 var nøyaktige (8).
Forskere fra Universitetet i Heidelberg samlet 50 legemiddel-relaterte spørsmål som ChatGPT besvarte (9). Svar fra chatboten ble vurdert av 6 sykehusfarmasøyter i forhold til innhold (korrekt, ufullstendig, feil), til pasientbehandling (mulig, utilstrekkelig, ikke mulig), og legemiddelsikkerhet (ingen, lav, høy risiko). De fant at 13 av 50 svar oppfylte kravene om korrekt innhold og tilstrekkelig informasjon til å kunne brukes i behandling uten risiko for pasientsikkerhet. Svarene til ChatGPT på samme spørsmål varierte over tid og bare 3 av 12 svar var identiske når de ble stilt på nytt (9).
De overnevnte studiene er bare noen få eksempler fra et eksponentielt økende antall publikasjoner om KI i helsevesenet. De peker på problemer med validitet og reliabilitet av ChatGPT, inkludert problemer som for eksempel feile eller falske svar, samt fiktive referanser og påstander. Vi ser at forskerne har noe ulike tilnærminger for å vurdere software basert på KI. Det vanlig at en metode i studien (informasjon og svar fra menneske) vurderes samtidig som det representerer gullstandarden. Noen kliniske farmakologer og farmasøyter diskuterer også eksplisitt at studien er motivert av en mulig konkurransesituasjon mellom dem selv og chatboten i arbeidslivet. Dette peker på et behov for en mer rettferdig og mindre biased tilnærming for å vurdere denne type verktøy i kommende studier. Merk at ChatGPT ikke søker på Internett direkte, men begrenser seg til det tekstmaterialet den er trent i. ChatGPT er trent i tekstgjenfinning, kan huske kontekst, men søker ikke etter kunnskap (4).
Bruk av KI i RELIS
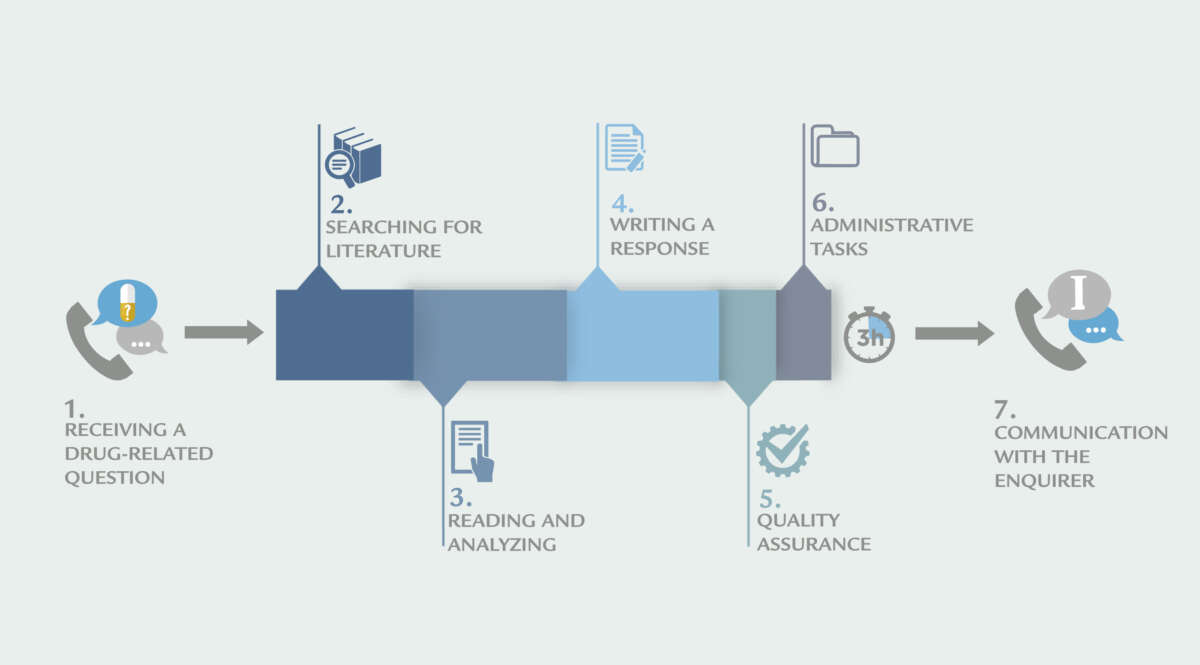
Verktøy som ChatGPT kan ifølge farmakologene i Odense for eksempel brukes til skrivestøtte, dataanalyse i farmakogenomikk eller til å frembringe automatiske svar for TDM-resultater (4). Det kan brukes til å raskt etablere viktige referanser for en problemstilling, og i tillegg oppsummere innholdet (se søkemotorer basert på KI ovenfor). Eldre søkemetoder basert på emneord som medisinske og helsefaglige termer (MeSH) for gjenfinning av litteratur kan med fordel bli supplert av KI-basert tekstgjenfinning. Søkemetoder basert på nøkkelord eller tekstord gir erfaringsmessig mye bakgrunnsstøy (10), noe som er tidkrevende for vår stab. For komplekse henvendelser til RELIS, med komorbiditet og polyfarmasi samt preferanser hos pasienten, kan tradisjonelle søk i litteraturen lett bli unøyaktige. Her har vi erfart at det trengs kunnskap og kompetanse i staben for å diskutere og formulere et tilpasset svar. Svaret kan også inneholde en forventning om en sekvens av tiltak eller alternative tiltak som krever nøye gjennomsyn. I utforming av slike deler av et svar vil det være spennende å bruke skrivestøtte (ikke med hensyn til innhold, men utforming) fra en chatbot. Referanse 5 gir perspektiver på sterke og svake sider ved ChatGPT i forhold til tema innen klinisk farmasi, og peker på at legemiddelsikkerhet og bivirkningsdiagnostikk per i dag er utfordrende. Endelig åpner KI for at RELIS kan trene chatboter for eget formål, og med egne datasett. Figuren under viser fremgangsmåten til RELIS for å utarbeide svar på henvendelser, og det synes som at KI har en rekke muligheter for å effektivisere og forbedre arbeidsmetoden vår!